Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)

Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)

Administrator
|
Mikä olisi kätevä tapa poimia erilleen osa merkkijonosta (VAR-operaatio?)
Tarvitsen opiskelijanumeron, joka on upotettuna osaksi pitkähköä merkkijonoa, jossa eri elementit on erotettu kaksoispistein. Ohessa "Bond-tyyliin" anonymisoitu näyte datasta (yksi kustakin yliopistosta, joiden opiskelijoita ao. (suoritus)datassa esiintyy; NA = ei yliopisto-opiskelija): -------------------------------------------------------------------------- urn:schac:personalUniqueCode:int:studentID:helsinki.fi:007007007 urn:mace:terena.org:schac:personalUniqueCode:int:studentID:aalto.fi:12345U urn:schac:personalUniqueCode:int:studentID:uta.fi:006006 urn:schac:personalUniqueCodeint:studentID:jyu.fi:00500500 urn:schac:personalUniqueCode:int:studentID:tut.fi:004004 urn:schac:personalUniqueCode:int:studentID:hanken.fi:003003 urn:schac:personalUniqueCode:int:studentID:utu.fi:002002 urn:schac:personalUniqueCode:int:studentID:tut.fi:001001 NA --------------------------------------------------------------------------Tavoitteena saada siis aikaan uusi muuttuja, jonka sisältö olisi vastaavasti: --------- 007007007 12345U 006006 00500500 004004 003003 002002 001001 NA --------- Katsoin kyllä Survon helpistä: https://www.google.com/search?q=VAR+survo.fi+help mutten päässyt eteenpäin tästä kohdasta: pos(S,p,string) is a useful auxiliary function giving the position of 'string' in the string variable S after the 'p'th position. koska en keksinyt tapaa viitata merkkijonon VIIMEISEEN kaksoispisteeseen. Ehdotuksia? |
Re: Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)
|
Administrator
|
En alkanut miettimään miten viimeisen kaksoispisteen saisi yleisesti ottaen etsittyä stringistä VAR:issa, kun tuon esimerkkisi perusteella tilanteessa on niin paljon muuta säännönmukaisuutta.
Tässä esim. yksi tapa hoitaa asia kohtuullisen näppärästi tässä tapauksessa: *DATA KIMMO,A,B,C,D DSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS CID Aurn:schac:personalUniqueCode:int:studentID:helsinki.fi:007007007 *urn:mace:terena.org:schac:personalUniqueCode:int:studentID:aalto.fi:12345U *urn:schac:personalUniqueCode:int:studentID:uta.fi:006006 *urn:schac:personalUniqueCodeint:studentID:jyu.fi:00500500 *urn:schac:personalUniqueCode:int:studentID:tut.fi:004004 *urn:schac:personalUniqueCode:int:studentID:hanken.fi:003003 *urn:schac:personalUniqueCode:int:studentID:utu.fi:002002 *urn:schac:personalUniqueCode:int:studentID:tut.fi:001001 BNA * *FILE COPY KIMMO TO NEW KTE1 / NEWSPACE=80,10 *.......................................................................................................................... *VAR PAIKKA:S30,OPNUM:S20 TO KTE1 *PAIKKA=MISSING OPNUM=MISSING *.......................................................................................................................... *pos1=pos(ID,helsinki.fi) *pos2=pos(ID,aalto.fi) *pos3=pos(ID,uta.fi) *pos4=pos(ID,jyu.fi) *pos5=pos(ID,tut.fi) *pos6=pos(ID,hanken.fi) *pos7=pos(ID,utu.fi) *pos8=pos(ID,tuni.fi) *erotin=pos(PAIKKA,:) *VAR str(PAIKKA)=str(ID,pos1) TO KTE1 / SELECT=PAIKKA,MISSING *VAR str(PAIKKA)=str(ID,pos2) TO KTE1 *VAR str(PAIKKA)=str(ID,pos3) TO KTE1 *VAR str(PAIKKA)=str(ID,pos4) TO KTE1 *VAR str(PAIKKA)=str(ID,pos5) TO KTE1 *VAR str(PAIKKA)=str(ID,pos6) TO KTE1 *VAR str(PAIKKA)=str(ID,pos7) TO KTE1 *VAR str(PAIKKA)=str(ID,pos8) TO KTE1 *VAR str(OPNUM)=str(PAIKKA,erotin+1) TO KTE1 / SELECT=OPNUM,MISSING * *FILE SHOW KTE1 Tässä lisäksi muutama muu idea: Jos tuon alkuosan pituus (niitä yliopistojen mukainen määrä) on jotenkin (vaikka manuaalisesti) ongittu esiin, niin tokihan siitä on helppo ottaa erilliseen muuttujaan vain se loppuosa pos():a käyttäen (tai kirjoittaa tyhjää alkuosan päälle sopivan pituuden verran). Jos loppuosa (opiskelijanumerot) alkaisivat aina (tietyllä) numerolla, niin voisi etsiä pos():lla stringejä :0, :1 jne. Jos loppuosa kokonaan numeerinen, niin FILE CONVERTilla voisi muuntaa kaikki paitsi numerot välilyönneiksi. |
Re: Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)
|
Administrator
|
Thanks, Reijo! :) Tuo toimii.
Olit jopa lisännyt ("kaukaa-viisaasti") korkeakouluvalikoimaan TUNI:n, tuon uuden uljaan Tampereen yliopiston, vaikkei sitä (vielä!) esiintynytkään tässä datassa. Datahan on, kuten valistuneimmat lukijat saattoivat ehkä arvata, IODS-kurssiltani: https://blogs.helsinki.fi/thinkopen/welcome-open-data-science/ Datan tuottaa Excel-muodossa HY:n MOOC-kurssien alustan https://mooc.helsinki.fi (Moodlerooms-yhtiön toteutus avoimen lähdekoodin Moodle-oppimisympäristöstä) arviointikirja (gradebook). Excel siirtyy Survo R:n suojiin R niin kuin rutiinilla: grades <- read.xlsx(xlsxFile = "IODS2018-Grades-20190114.xlsx", colNames=TRUE)ja FILE SAVE R>grades TO NEW GRADES / VARLEN=74minkä jälkeen tilanne näyttää seuraavalta: FILE STATUS GRADES Copied from R data frame grades FIELDS: (active) 1 SA_ 13 First.name 2 SA_ 28 Surname 3 SA_ 74 ID.number 4 SA_ 11 Institution 5 SA_ 20 Department 6 SA_ 38 Email.address 7 SA_ 18 Course.total.(Real) 8 SA_ 18 Workshop:.RStudio.Exercise.1.(palautus).(Real) 9 SA_ 18 Workshop:.RStudio.Exercise.1.(arviointi).(Real) 10 SA_ 18 Workshop:.RStudio.Exercise.2.(palautus).(Real) 11 SA_ 18 Workshop:.RStudio.Exercise.2.(arviointi).(Real) 12 SA_ 18 Workshop:.RStudio.Exercise.3.(palautus).(Real) 13 SA_ 18 Workshop:.RStudio.Exercise.3.(arviointi).(Real) 14 SA_ 18 Workshop:.RStudio.Exercise.4.(palautus).(Real) 15 SA_ 18 Workshop:.RStudio.Exercise.4.(arviointi).(Real) 16 SA_ 18 Workshop:.RStudio.Exercise.5.(palautus).(Real) 17 SA_ 18 Workshop:.RStudio.Exercise.5.(arviointi).(Real) 18 SA_ 18 Workshop:.RStudio.Exercise.6.(palautus).(Real) 19 SA_ 18 Workshop:.RStudio.Exercise.6.(arviointi).(Real) 20 SA_ 10 Last.downloaded.from.this.course END Survo data file GRADES: record=555 bytes, M1=29 L=64 M=20 N=235 Tässä "tehtävässä" on siis kyse muuttujasta "ID.number". Huom! FILE SAVE (hyvästä syystä) vinkkaa tuossa välissä, että muuttujien nimet on syytä muuttaa Survolle yksikäsitteisiksi, siis 8 ekan merkin osalta (nythän mjat 8-19 ovat kaikki Survon näkökulmasta "kutsumanimeltään" Workshop). Niin myös tein (samalla karsin turhia muuttujia ja muutin Workshop-muuttujat numeerisiksi): FILE CREATE GRADES / tehdään ihan uudelleen (num.mjat ym.; turhat pois jne.!) Copied from R data frame grades FIELDS: (active) 1 SA_ 13 First.name 2 SA_ 28 Surname 3 SA_ 74 ID.number HAKA-login: opnro embedded (deep)... THIS IS THE KEY TO HAPPINESS! 4 SA_ 9 opnro ...kunhan se siirretään tuonne! 5 SA_ 38 Email.address 6 NA_ 4 WS1s RStudio1: Tools and methods for open ... (submit) 7 NA_ 4 WS1a RStudio1: Tools and methods for open ... (assess) 8 NA_ 4 WS2s RStudio2: Regression and model validation (submit) 9 NA_ 4 WS2a RStudio2: Regression and model validation (assess) 10 NA_ 4 WS3s RStudio3: Logistic regression (submit) 11 NA_ 4 WS3a RStudio3: Logistic regression (assess) 12 NA_ 4 WS4s RStudio4: Clustering and classification (submit) 13 NA_ 4 WS4a RStudio4: Clustering and classification (assess) 14 NA_ 4 WS5s RStudio5: Dimensionality reduction techniques (submit) 15 NA_ 4 WS5a RStudio5: Dimensionality reduction techniques (assess) 16 NA_ 4 WS6s RStudio6: Analysis of longitudinal data (submit) 17 NA_ 4 WS6a RStudio6: Analysis of longitudinal data (assess) END ............................................. FILE SHOW GRADES-TMP MASK=AAA--A-AAAAAAAAAAAA- FILE COPY GRADES-TMP TO GRADES FILE SHOW GRADES / tässä S-mjien (WS*) "-" muuttuu nolliksi, mikä on very OK tällä kertaa! ..............................Sitten vielä pientä hienosäätöä muuttujien nimiin ym.: FILE UPDATE GRADES Copied from R data frame grades FIELDS: (active) 1 SA_ 13 etunimi 2 SA_ 28 sukunimi 3 SA_ 74 ID.number HAKA-login: opnro embedded (deep)... THIS IS 4 SA_ 9 opnro ...kunhan se siirretään tuonne! 5 SA_ 38 email 6 NA_ 4 WS1s RS1: Tools and methods for open ... (submit) (###.#) 7 NA_ 4 WS1a RS1: Tools and methods for open ... (assess) (##.#) 8 NA_ 4 WS2s RS2: Regression and model validation (submit) (###.#) 9 NA_ 4 WS2a RS2: Regression and model validation (assess) (##.#) 10 NA_ 4 WS3s RS3: Logistic regression (submit) (###.#) 11 NA_ 4 WS3a RS3: Logistic regression (assess) (##.#) 12 NA_ 4 WS4s RS4: Clustering and classification (submit) (###.#) 13 NA_ 4 WS4a RS4: Clustering and classification (assess) (##.#) 14 NA_ 4 WS5s RS5: Dimensionality reduction techs (submit) (###.#) 15 NA_ 4 WS5a RS5: Dimensionality reduction techs (assess) (##.#) 16 NA_ 4 WS6s RS6: Analysis of longitudinal data (submit) (###.#) 17 NA_ 4 WS6a RS6: Analysis of longitudinal data (assess) (##.#) ENDja nyt Reijon ohjeilla pääsen näppärästi eteenpäin ja saan aikaan kaipaamani opnro-muuttujan. Yes! Kommentit noihin muihin ideoihin, joita Reijo listasi viestin lopussa: RS>Jos tuon alkuosan pituus (niitä yliopistojen mukainen määrä) on jotenkin (vaikka manuaalisesti) ongittu esiin, niin tokihan siitä on helppo ottaa erilliseen muuttujaan vain se loppuosa pos():a käyttäen (tai kirjoittaa tyhjää alkuosan päälle sopivan pituuden verran). En tee sillä alkuosalla mitään, mutta olen kyllä onnellinen, että Moodlerooms Inc. sai (vuoden painostuksen jälkeen) aikaan tuon lisäyksen; siis että korkeakoulujen ym. yhteisellä HAKA-loginilla kirjautuminen jättää tuon ID.number-jäljen, josta (sentään) saa kaivettua opnron. Aiempina vuosina MOOCilla kirjautuneista ei ollut mitään muuta tunnistetietoa kuin sähköpostiosoite (!!). Iso edistysaskel siis. "Sivutuotteena" tuli tuo tieto siitä, mistä yliopistosta kukin (HAKA-kirjautunut) on. MOOCille voi yhä kirjautua myös muilla tavoin (tai jopa toimia tiettyyn pisteeseen asti vierailijatunnuksilla), jolloin näitä tietoja ei opettajalle tule (ja siten suoritusten myöntäminen voi olla vaikeaa). RS>Jos loppuosa (opiskelijanumerot) alkaisivat aina (tietyllä) numerolla, niin voisi etsiä pos():lla stringejä :0, :1 jne. Eivät näytä alkavan, vaan on kovin kirjavaa. Yleisin alkunumero on nolla (sic), joka yleensä häviää eri vaiheissa, esim. Excelöitynä, jos koodi alkaa sillä (Survon S-muuttujien ansiosta se säilyy, ja tässä vielä siksi, että se on keskellä tuota rimpsua eikä alussa - jokin hyöty tuosta alkuosasta!). :) RS>Jos loppuosa kokonaan numeerinen, niin FILE CONVERTilla voisi muuntaa kaikki paitsi numerot välilyönneiksi. Ei näytä edes tuo pätevän, vaan "opnro" voi sisältää myös kirjaimia. |
Re: Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)
|
|
Eikös tuossa viimeisen kaksoispisteen edellä ole aina ":fi", jolloin voi käyttää pos1=pos(ID,.fi:) VAR str(OPNUM)=str(ID,pos1+4) TO KTE1 ?? |
Re: Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)
|
Administrator
|
No niinpä tietysti! Kiitos Juha, hyvä huomio.

|
Re: Merkkijonon osan poiminta erilleen (VAR-operaatiolla?)
|
Administrator
|
Enpä maanantaina tuota Juhan esittämää, todella simppeliä mahdollisuutta tajunnut. Kävi kuten niin usein ennenkin (ks. esim. keskusteluryhmän arkisto): Survon tehokäyttäjien joukosta löytyy aina ovelia ratkaisuvaihtoehtoja, joita ei ole itse tullut ajatelleeksi (tai ei vain huomaa, kun on keskellä jotain työtä, joka pitäisi saada nopeasti valmiiksi).
Suuremmassa mittakaavassa vastaava vertaistukisysteemi on Stack Overflow, jossa näyttää olevan esim. R-aiheisia kysymyksiä n. neljännesmiljoona, Python-aiheisia yli miljoona - ja löytyypä sieltä yksi kysymys myös hakusanalla Survo :) (*). Tuosta alustasta oli mm. kirjani teossa paljon hyötyä, samoin kurssilaisilleni juuri tuolla IODS-kurssilla. (*) https://stackoverflow.com/questions/35876652/entity-framework-inheritance-tph-adding-discriminator-on-every-query Reijon ehdotuksessa jo oli tuo osamerkkijonon hakeminen pos-funktiolla, ja siinä kivana sivutuotteena tuli samalla mahdollisuus tallettaa tieto opiskelijan yliopistosta omaan muuttujaansa. VAR-komennon help-sivulla pos-funktion esimerkissä haetaan vain yhtä merkkiä. Tällainen esimerkki, jossa haetaan merkkijonoa, voisi olla hyvä täydennys siihen. Alla (lopulta tänään aikaansaamani) yhteenveto noista tuloksista, jotka sain ma-iltana valmiiksi. Kiitos vielä avusta ja talvista viikonloppua kaikille! - Kimmo 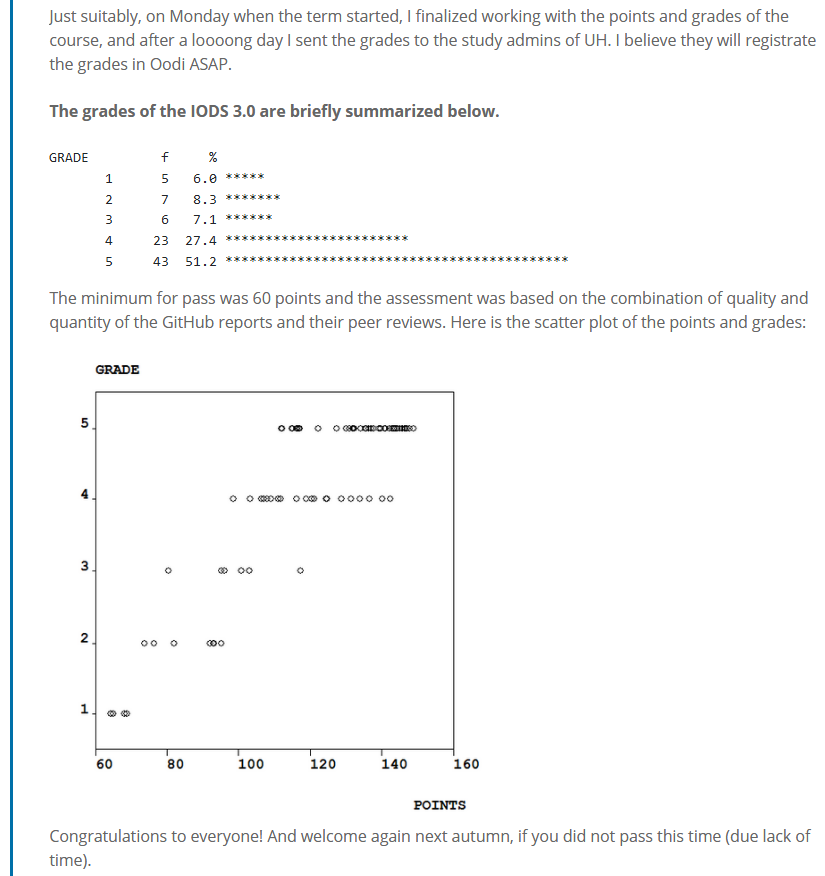
|
«
Return to Survo keskustelu [in Finnish]
|
1 view|%1 views
| Free forum by Nabble | Edit this page |